1. Évolutions techniques
La release de milieu d’année n’a pas vocation à mettre à jour la « stack technique » et ses composants qui reste conforme aux éléments indiqués dans la release Eldorado de début d’année.
En ce sens, on notera que les versions des principaux composants sont les suivantes :
- Java : version 17
- Primefaces 12.0
- Serveur d’application Apache Tomcat : version 10.1.1
- Moteur de recherche ElasticSearch : version 8.5.0
- Moteur de files RabbitMQ : version 3.11.2
- Base de données PostgrSQL : version 15.0
- Base de données Oracle : version 19c
- Conversion Aspose : version 22.7
- Antivirus Clamav : version 0.105.1
- Apache Tika 2.5.0
- Honeywell CT 40, Android 11
- Côté navigateur, on supporte toujours Chrome, Edge Chromium et Firefox
Côté OS, de la nouveauté liée aux évolutions de la politique commerciale de RedHat. L’application est maintenant compatible Rocky Linux 8 et reste évidemment compatible avec Redhat Entreprise Linux en version RHEL 8.
2. Evolutions fonctionnelles
Les évolutions fonctionnelles sont axées sur cette release sur des besoins métiers :
- Salle de tri et tags
- Chiffrement des données
- Amélioration de la restitution
- Cloisonnement des référentiels métiers
- Traitements des versements
- Paramétrage des facettes
- Export/import des libellés
- Extension des API pour INGEST et les référentiels métiers
- Extension des traitements associés au contrôle de cohérence
- Quelques bonus : Gestion des services fermés, suppression des mots-clés non référencés, la recherche contextuelle, des infobulles sur les droits et les notifications, …
Salle de tri et tags, vers une nouvelle manière de travailler !
La Salle de tri a pour objectif de :
- Sélectionner et « tagguer » les documents afin de mieux structurer et organiser son travail au sein de la salle de tri.
- Effectuer des modifications en masse sur le sort final, date de destruction et date de communicabilité
- Lancer des opérations d’anonymisation, de traitement du sort final et de restitution de manière centralisée
Elle permet d’opérer indifféremment sur les documents physiques ou électroniques et de traiter des volumétries considérables tout en centralisant l’opération de recherche.
Un verrouillage automatique de la salle de tri permet de s’assurer que les opérations sont menées à bien.
Le chiffrement des données enfin disponible !
Le chiffrement des données est prévu dans la norme NF Z 42-013 au point 6.2 intitulé « Chiffrement des documents archivés ».
Le chiffrement des données vise à renforcer la sécurité des archives électroniques dans un SAE en utilisant le chiffrement symétrique et asymétrique. Les fichiers sont chiffrés via des clés de chiffrement symétrique (AES) pour une protection rapide et optimale. Ensuite, ces clés sont elles-mêmes chiffrées avec du chiffrement asymétrique (RSA) via un gestionnaire de clés externe.
Spark Archives conserve les clés et l’alias du certificat pour déchiffrer les fichiers conservés dans les magasins avant toute utilisation dans l’application.
Si les fichiers sont conservés dans un magasin électronique chiffré, dès lors que l’on effectuera une action sur ces fichiers, on fera appel au service de déchiffrement. Cela sera valable lors du visionnage, d’une demande de téléchargement, une demande d’audit, etc.
Ce fonctionnement a été mis en place dans des couches « bas niveau » de l’application afin de rendre transparent aux utilisateurs le fait que les documents soient chiffrés.
Pour les utilisateurs, il n’y a aucun impact visuel. Le chiffrement et le déchiffrement s’effectuent de manière transparente.
Dans cette mécanique, la gestion des clés est de la responsabilité des clients qui sont seuls détenteurs de celles-ci à travers leur gestionnaire de clés.
L’ amélioration de la restitution et une homogénéisation des processus
Le module de restitution a été revu afin d’être plus homogène avec le reste des autres modules ainsi que pour apporter plus de robustesse dans les différents traitements opérés.
Le module de restitution est utilisé pour restituer les documents physiques et les documents électroniques ainsi que leurs métadonnées associées.
La restitution peut être utilisée pour répondre à 2 objectifs principaux :
1. La réversibilité des données afin de changer de solution d’archivage
2.La restitution des documents à une autre entité (filiale)
Le processus de restitution permet de générer des paquets contenants :
1. Les métadonnées des dossiers et documents physiques et électroniques
2. Les fichiers électroniques (uniquement pour les documents électroniques)
3. Les fichiers de preuve (uniquement pour les documents électroniques)
4. La liste des éléments à restituer (avec leur localisation pour les documents physiques)
Ce module permet également le lancement d’opérations de traitement du sort final comme la destruction de fichiers électroniques, mais également le lancement d’opération d’anonymisation sur des documents physiques et/ou électroniques.
L’extension du cloisonnement pour des tenants individualisés à l’extrême
L’extension du cloisonnement a pour objectif de fluidifier, simplifier et étendre cette notion à de nouvelles opérations archivistiques et référentiels métiers.
La plupart des opérations archivistiques (versement, demandes, etc.) sont déjà cloisonnées ainsi que certains référentiels (utilisateurs, services, plan de classement).
Les nouvelles opérations archivistiques concernées sont les suivantes :
- Le module GED
- La liste des contrôles de cohérence
- Les mouvements inter-centre pour les documents physiques et contenants
- La salle de tri
Les nouveaux référentiels concernés sont les suivants :
- Les magasins électroniques et les centre d’archives physiques y compris les emplacements physiques, le pilotage des emplacements, les catégories et niveaux d’emplacements.
- La politique d’archivage (les règles de conservation, de communicabilité, le type de sort final et de support, le type de contenant et d’anonymisation ainsi que les typologies)
- La gestion des services, types de service et d’association
- La gestion des utilisateurs et des niveaux d’accès (confidentialité et confidentialité médicale)
- La conversion et les opérations de migrations
- Les valeurs des listes d’autorités, les valeurs des mots-clés y compris les valeurs présentes dans les listes prédéfinies suivantes : motifs de non trouvé, niveau d’urgence, type de sortie de pièces des demandes ; types d’insertion, motifs de prêt
Une simplification du paramétrage permet de facilement configurer une instance afin que celle-ci soit en mode cloisonnée ou non.
Le workflow de reprise sur erreurs des versements optimisés
Les versements s’effectuent par un workflow qui comprend plusieurs étapes de contrôles.
Afin d’améliorer le workflow de versement, les actions sur les écrans de traitement des versements ont été améliorés ainsi que les traitements unitaires sur les différents documents électroniques (format autorisé, conversion, réplication, génération des preuves et horodatage RFC 3161).
Les actions sur les listes de versements permettent de relancer l’ensemble des versements selon leur statut.
Ces traitements ont pour objectif de simplifier l’administration courante des versements en erreurs afin de reprendre, résoudre et débloquer ces derniers sans le faire unitairement.
Cette fonctionnalité est valable à la fois pour les versements de documents physiques, électroniques voire hybrides.
Un gain de temps important à la clé pour traiter en masse vos versements !
Cette fonctionnalité est valable à la fois pour les versements de documents physiques, de documents électroniques voire des documents hybrides.
Le paramétrage des facettes graphiques individualisés pour TOUS les écrans de résultat de recherche Elastic Search
Les facettes affichées dans les résultats de la recherche permettent aux utilisateurs de filtrer l’écran de résultat de recherche à l’aide des filtres disponibles.
Les écrans de résultat de recherche portent sur la plupart des opérations archivistiques !
Les facettes graphiques qui sont affichées dans l’ensemble des écrans de résultat de la recherche deviennent paramétrables fonctionnellement !
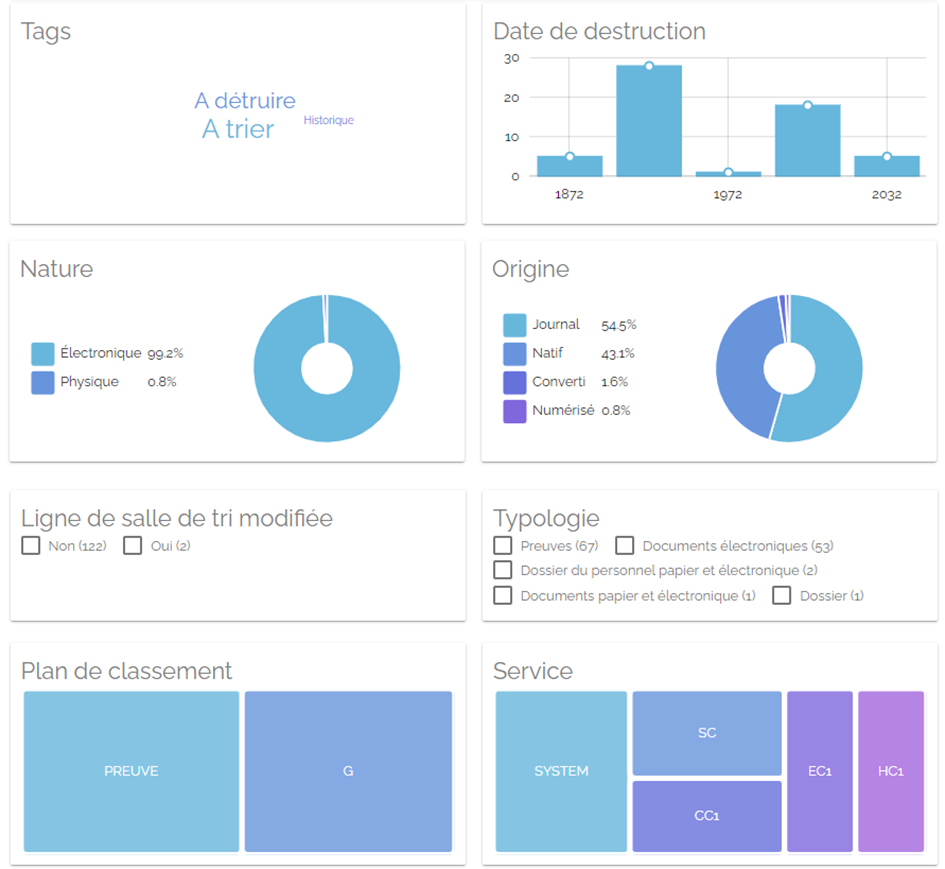
L’export/import et la gestion des libellés
La gestion des libellés gère tous les libellés affichés dans l’application qu’il s’agisse du libellé d’un bouton, des menus, d’une entrée du plan de classement, d’une nouvelle métadonnée, une modification d’un libellé, etc.
L’idée est ici d’améliorer le service rendu aux utilisateurs afin de leur faciliter l’export de l’ensemble des libellés et l’import de ces libellés « modifiés » à travers un fichier CSV.
La gestion des thèmes, de l’écran d’authentification
La gestion des thèmes permet de personnaliser le rendu graphique de l’application.
A cette occasion, Spark Archives applique sa nouvelle charte graphique .
Dans ce cadre, les évolutions suivantes ont été introduites :
1. La gestion du thème par défaut pour les utilisateurs n’ayant pas de thème particulier ;
2. L’internationalisation des thèmes dans les différentes langues de l’application;
3. La configuration de la page d’authentification à l’application (fond d’écran, logo, texte).
L’extension des API aux référentiels métiers et INGEST
Les API de Spark Archives existent depuis de nombreuses années et sont enrichies de manière régulière en fonction des besoins de nos clients et partenaires intégrateurs.
Dans cette logique, les API ont été étendues au niveau :
↦ Des référentiels : les API permettent maintenant de gérer :
- Les règles de conservation ;
- Les règles de communicabilité ;
- Les types de sort final ;
- Les valeurs d’autorité ;
- Les mots-clés
Pour les API, il s’agit de permettre la création, modification et suppression.
↦ D’INGEST : L’API permet maintenant de :
- Déposer un lot/dossier zippé et le nom du flux INGEST à utiliser ;
- De lancer un traitement INGEST ;
- De connaitre l’état d’un lot (déposé, en cours de traitement, terminé ou en erreur)
Ces API sont mises à disposition sur demande et permet d’augmenter l’interconnexion de Spark Archives avec d’autres logiciels et faciliter l’intégration par nos partenaires.
Vers une amélioration dans la finesse de gestion des erreurs dans le contrôle de cohérence
Afin de gagner en finesse sur l’analyse des erreurs qui peuvent être remontées par le contrôle de cohérence, une amélioration des messages et de la traçabilité de celles-ci dans le temps a été mise en place.
En effet, il s’avère que certaines erreurs techniques peuvent être remontées à un instant t du fait d’indisponibilité technique et que celles-ci ne sont plus présentes à un instant t +1.
Dans ces cas, tracer ces modifications et mieux les comprendre/appréhender d’un point de vue utilisateur est une nécessité.
Le contrôle de cohérence trace ainsi les erreurs qui surviennent de manière répétée à travers un code couleur et intègre la traçabilité issue des anciens contrôles de cohérence. Le code couleur associé au lignes d’un contrôle de cohérence indique si un contrôle sur un document est valide du fait de la résolution de l’erreur ou de l’indisponibilité technique.
Ces éléments facilitent grandement la vie de l’utilisateur qui peut ainsi trier les erreurs remontées et les identifier rapidement. Ils sont également tracés dans le journal des tâches.
Des bonus !
Gestion des services fermés
Vous pouvez dorénavant, grâce à un droit applicatif rendre possible la saisie des archives sur des services fermés pour la gestion des archives intermédiaires et surtout historiques !
Recherche contextuelle
Vous pouvez facilement intégrer une page de résultat de recherche en fonction de paramètres directement renseignés dans l’URL à partir des applications métiers en utilisant la recherche contextuelle.
Dans le cadre d’échanges inter-application, vous avez désormais la possibilité d’accéder directement à une page de résultat de recherche contextualisée en fonction d’une application métier.
Par exemple, dans le domaine hospitalier, il est souvent nécessaire pour une secrétaire médicale de pouvoir à partir de son application cliquer sur un lien patient pour accéder à l’ensemble des dossiers du patient archivé dans Spark Archives.
Cette nouvelle fonctionnalité permet de renseigner des paramètres dans l’URL du résultat de recherche pour arriver sur la page escomptée.
Vous pouvez également utiliser cette fonctionnalité pour conserver le lien d’une recherche que vous faites fréquemment.
Infobulle sur les droits et les notifications
Mieux connaître la définition et fonction d’un droit applicatif dans les différentes langues de l’application est dorénavant possible en survolant simplement le droit applicatif.
On s’arrête là pour les principales nouveautés et on notera que la nouvelle version intègre bien évidemment un certain nombre de corrections sur les anomalies détectées dans l’application.
Quentin RIAC, Herwann PERRIN & Jérôme BESNARD
Product Owner, Product Manager, R&D Manager